
VegBank FAQ
Frequently Asked Questions about the VegBank database and website.
Please select from the following questions, or browse through this file:
(clear highlighting on this page.)
What is VegBank?
Who runs VegBank?
What is a plot?
Where does VegBank get its plots and other data?
How do I find plots in VegBank?
How do I download VegBank data to my computer?
Why do I need to register? Why do I need to log in?
What is a dataset? What is the datacart?
What features does VegBank offer for analysis of plot data?
What are the best practices or standards of VegBank?
What is certification? When do I need to be certified?
What is a community?
What is a plant concept? What is a community concept?
What is your standard list of species/communities?
What is metadata?
Why are there so few soil variables in the soilObs table?
What is annotation?
How do I cite VegBank?
What is an Accession Code?
How is VegBank financed? How can I help VegBank operate financially?
How can I get help with VegBank? Is there a tutorial?
When can I sign up for a training workshop?
How does VegBank keep track of plot area? Why is the area negative sometimes?
Contacting VegBank Developers:
What if I find something not working in VegBank?
What are the VegBank Mailing Lists? How do I sign up?
How do I load plots into VegBank?
What is VegBranch?
How can I protect my plots in VegBank?
Is data from other countries allowed into VegBank?
How many plots can I add?
What if my plant species are not found in your list of taxa?
What if my community is not found in your list of community types?
What is your data model?
Is there more than one VegBank? Can I run my own VegBank to serve data from another Country?
General Questions
VegBank is the vegetation plot database of the Ecological Society of America's Panel on Vegetation Classification. VegBank stores data about vegetation plots and necessary supplemental data, such as a plant taxon database and community type database. VegBank's purpose is to allow plant Ecologists to submit and share data to allow permanent documentation of plot data, which will provide a permanent record of plots which define communities.
VegBank is operated by the Ecological Society of America's Vegetation Panel in cooperation with the National Center for Ecological Analysis and Synthesis. The development team for VegBank is listed on the contact page. Further participants can be found on the development history page.
The purpose of plots is to record the vegetation and its environmental context. A plot may be contained by a single bounded area, such as a 50m x 20m rectangle. It could also consist of smaller subplots which sample vegetation over a large range. While we encourage plots to have boundaries and definite size, VegBank also accepts relevés that have no bounds as valid plots. An observation is a one-time record of vegetation present in a plot. So multiple observations of a plot could be made at different times, producing different values for both vegetation present (both in which taxa are present and its abundance as well as environmental variables, such as soil characteristics).
Plots in VegBank come from the users who decide to contribute their plots. VegBank does not fund plot collection, but see ourselves as a means for those who do collect plots to share their data. There are two major implications of this:
1) We do not guarantee the accurateness of the data in VegBank. Users are allowed to annotate (make notes and reinterpret plants and plots) to share with other users their opinions about the data already in VegBank. [Some of the annotation features are still in development.]
2) We need users to share their data. There are many different reasons users share their data. Some are required to share their data by their grants, but don't want to deal with the hassle of setting up computer servers and software to manage this. Some use VegBank as a means of collaborating with others in data analysis. Others have finished analysis and are eager to find a use for their hard work other than being filed away to collect dust. Still others see the foresight in adding their data to the greater body of knowledge on a public site like VegBank.
Other data, like plants and communities, come from VegBank's users, but rely heavily on VegBank users like the organizations USDA Plants and NatureServe to provide this data.
You can search for plots with two different pages in VegBank.
1) a very simple search, where you can specify one or more of the following: plant found on the plot, community to which the plot is interpreted, state/province in which the plot is located.
2) a more complex query with many options for searching, allowing multiple plants, places, and communities to be specified. It also allows you to search by other fields, like elevation.
Once you have found plots (or communities or plots) of interest, they may be added to the datacart by clicking on the "plus" datacart icon () next to the item of interest. You can perform various functions on the datacart by clicking on the "download" link next to the datacart at the top of the screen.
Once you have added plots to the datacart, you can download them from the "download" link next to the datacart icon near the top of any page in VegBank. Once you click that link, you will see a menu of options that you can perform with the data in your datacart, including downloading the data.
For more information on adding plots to the datacart, please see the FAQ topic on how to search for plots.
If you are having problems downloading a large set of data, try downloading fewer plots at a time (around 250 or less). We apologize for the inconvenience.
You don't need to register to use most of VegBank's features. Registration is only required if you want to VegBank remember one or more datasets or if you want to upload data to include in the VegBank archive (this also requires certification).
A dataset is a set of items (plots, communities, or plants) that you are interested in. The datacart is the current or active dataset to which you can add items when searching or viewing data. You add items to the datacart by clicking the "add to datacart" icon:
If you are not logged in, you have access to a single datacart. If you have items in your datacart and then log in, those items are retained in your datacart. If are logged in, you can have multiple datasets that are remembered the next time you log in. You can then activate different datasets to become the current datacart, performing various functions on the datacart, such as viewing a constancy table, mapping plots, or querying for plots that match plants or communities in a dataset. All the dataset and datacart functionality is available from the DATASETS link in the upper right of all pages in VegBank.
To create a new datacart, you must log in, then you can click the download datacart link at the top of the page and click the "create a new datacart" link under "Advanced Datacart Features." This saves the current datacart in your list of datasets and creates a new empty datacart to which you can add new items.
VegBank does not have analysis tools. Other groups have done a good job making tools for analysis, and we encourage users to find data in VegBank, then export into a format of your choice, then work on analysis with a program like PC-Ord.
VegBank has a very flexible structure that allows legacy data to be added, as well as data that do not conform to our best practices. We do encourage users to conform to the best practices standards as described in the standards document, Guidelines for Describing Associations and Alliances of the U.S. National Vegetation Classification . This document will help you understand the best practices of plot collection in VegBank for purposes of classification.
Certification is required for VegBank features that allow you to add data to the database. You can become a certified user by registering to be a VegBank user, then filling out a certification application. This means that your user profile will be public, as well as some of your certification questions (the application tells you what will be made public). This helps users understand who you are and what credentials are behind your opinions and plots in VegBank.
In overly simple terms, a community is a set of plant taxa that live adjacent to one another within a set of physical conditions. This community of co-occurring plants may be seen to repeat itself in a predictable pattern. One may classify (or interpret) a plot as belonging to a certain community type.
The Guidelines of the NVC (National Vegetation Classification) Standards document (version 3) provides more full definitions for two different levels of communities: association and alliance. It defines an association "as the basic unit of vegetation: A vegetation classification unit defined on the bases of a characteristic range of species composition, diagnostic species occurrence, habitat conditions and physiognomy." (pg. 21)
The broader alliance it defines as "A vegetation classification unit containing one or more associations, and defined by a characteristic range of species composition, habitat conditions, physiognomy, and diagnostic species, typically at least one of which is found in the uppermost or dominant stratum of the vegetation." (pg.23)
Communities are Concept-Based in VegBank, meaning they are defined by a combination of a name and a reference. See the What is a Concept? FAQ Topic for more information on Concepts.
Generally, people use only a plant name to refer to a particular plant taxon. However, names may mean different things to different people or at different times. When users view a plant in VegBank, they need to know what is meant by a plant name, hence only a name is not enough. A reference, or context, must be provided which gives the name meaning and defines what the taxon encompasses. When we mention a "plant concept" in VegBank, we mean this unique combination of name and reference. For example, one might mention "Carya ovata" according to (reference) "Radford, 1968." Each plant concept and community concept in VegBank has an Accession Code which provides unique identification for the plant concept. For more information, please see the VegBank Plant Taxonomy Overview.
Community Concepts function in exactly the same way, except that Community Concepts describe a community type, not a plant taxon.
VegBank does not have a standard list of taxa or communities. In VegBank, plants and communities have a Party Perspective which defines whether a plant or community is standard or not and what names may be used to describe it. VegBank has no Party Perspective of its own. However, USDA PLANTS 2002 data and NatureServe communities were initially loaded into the database and users are strongly encouraged to map any new plants or communities onto USDA's or NatureServe's standards. This allows other users, who may know nothing of your own views, to view information according to the USDA or NatureServe standards.
Metadata is plot data that defines not what was measured, but how it was measured. Cover Method and Stratum Method are examples of metadata. Plot size and stem sampling method might also be considered metadata. These data are often considered secondary in importance, but are essential when many different techniques are used to collect plots, as is the case with VegBank data.
Soil analysis techniques vary widely and thus make it difficult to define standard soil variables. We do recognize some standards, such as pH, percent clay, percent silt, percent sand. But other variables, such as Nitrogen ppm could be measured with different techniques, yielding different values for the same soil. We encourage users to input their soil values in user-defined fields where they can describe what techniques were used to analyze their soils.
Annotation is when users add their own opinions to plots that are already in the VegBank archive. This is a bit different from a plot author, who provides information about his or her own plot. Annotation can be grouped into three categories: 1) plant interpretation, 2) plot interpretation, and 3) notes.
Plant Interpretation means that you say which plant concept you think a particular plant on a plot actually is. This does not replace the author's view or interpretation, but simply adds it to the database.
Plot Interpretation means that you say which community concept you think a particular observation (of a plot) actually is. Similarly, this does not replace anyone else's interpretation of the plot, but adds your opinion to the database.
Notes are comments that you might have on a particular field value. These can be added to any field in the database, and are useful if you have some insight into an error or incomplete piece of data. For example, you could add a note to the elevation value of a plot saying that you do not think the elevation was as high as is claimed.
You may cite VegBank, as a whole or one or more elements, with the instructions on the citation page. That page also shows how to cite a description of VegBank.
An Accession Code is a unique combination of letters, numbers, and some periods which uniquely identify something in VegBank. Accession Codes are used to identify plots and observations, as well as methods, plant taxa, and community types. This allows communication about these elements to take place so that each party knows that they are mentioning the same thing. Accession Codes are important when VegBranch and VegBank communicate, because this helps the two databases align the different types of data, rather than repeating redundant information.
For those who want to know how a VegBank Accession Code works (this is not necessary!), it is broken into several alphanumerical parts, each divided by a period (.). An example Accession Code is that of Quercus alba, with reference of USDA 2002 : VB.PC.48413.QUERCUSALBAL
The first part is the database identifier (i.e. VB for VegBank), then a table identifier (i.e. PC for Plant Concept), then a record number (i.e. the primary key, 48413). Next, there is a confirmation code, which is a set of letters and numbers derived from something that is likely to make sense to a person. This means that we can see this code and may generally know that it is Quercus alba of some sort. The confirmation code also ensures that the accession code has not suffered from a typo, which could result in the mismatching of data without anyone's awareness. For example, if there was no confirmation code and you mistyped the 'PC' as 'Py', then the database would think you meant Party #48413. Worse, you could mistype the number as 48418 and a different plant would be referenced.
Finally, there may be a fifth segment of the accessionCode which identifies the time and date the record was accessed from the database mentioned in the first part of the accession code.
We are currently funded by the US National Science Foundation (NSF). We gratefully acknowledge the financial support of NSF. This project would not have been possible without the support provided by NSF grant DBI-9905838.
We are also funded through the US Geological Survey (USGS). We gratefully acknowledge the continuing financial support of the USGS Gap Analysis Program, as well as the encouragement of the US National Biological Information Infrastructure (NBII).
Eventually, we'd like to have a web feature that allows you to donate to our efforts. Until then, if you have a funding source for VegBank, please contact us at help@vegbank.org. We'd be more than happy to hear about it.
Learning More about VegBank
Yes! There is currently a set of instructions that walks the user through the main forms in VegBank. See the instructions page to start this.
We do offer training in VegBank and VegBranch. Training information can be found on the Professional Training page. We present workshops at the ESA annual meeting and periodically with groups who request special training. VegBank presents information about the next VegBank workshop here. You can sign up for a workshop from that page, if there is one in the near future, or you can request a training session by sending email to help@vegbank.org. We will try to offer special training session, but are limited in both time and funds for such purposes.
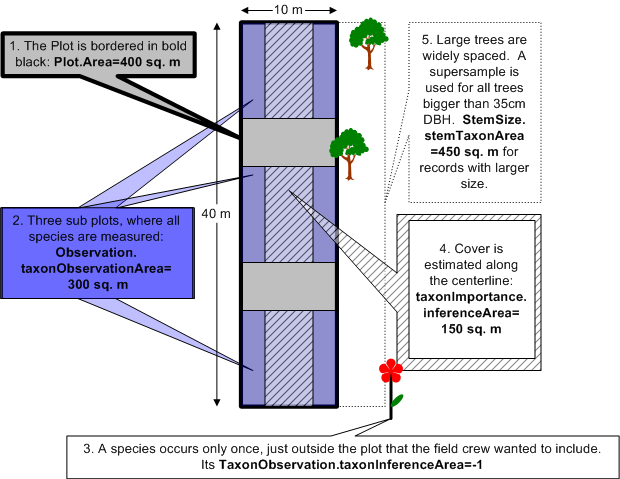
VegBank has several fields that store area values, recording the size of the plot in square meters. A simple value is not always sufficient, as sub-sampling and super-sampling are often used, as are dispersed subplots. Furthermore, sub- or super-sampling may be used only for certain species or even certain sizes of species. These complex situations require that many area fields be available in VegBank. Area of -1 indicates that there is no known area.
Explained graphically:
- Plot.Area - this is the size of the plot, including subplots and any interstitial space
- Observation.TaxonObservationArea - this is the area used to compile a complete list of species for the whole plot, omitting interstitial space
- TaxonObservation.TaxonInferenceArea - this is the area used to determine one particular species is present. It could be larger or smaller than Observation.TaxonObservationArea, overriding that value
- TaxonImportance.InferenceArea - this is the area used to calculate the importance values for one particular species. Overrides any of the above values.
- Observation.StemObservationArea - this is the area used to measure all stems on the plot.
- StemSize.StemTaxonArea - this is the area used to record a particular stem size for a particular species. Overrides the above value.
Contacting VegBank Developers
You should tell us about what wasn't working. Just send an email to help@vegbank.org and explain what it is that isn't working. Please be as specific as possible, i.e. what the URL was when the error occurred, what the search criteria were if you were searching for something, the time and date the error occurred, etc. Users who report errors help us improve the VegBank experience for everyone. Thank you!
There are two VegBank mailing lists. The Users list is for VegBank users to post questions and comments to each other. The VegBranch list is similar, but covers topics related to VegBranch. The development team is also on these lists and can answer questions. The advantage to using this list is that an archive of questions and answers is being built that users can search. These lists are described in detail in the contact page. If you have a question or comment for the development team that you do not want posted to a public archive, please email us at help@vegbank.org.
Loading Data into VegBank
Plots can be loaded into VegBank with the desktop tool called VegBranch. VegBranch can then create an XML document (a particular format of text file) that can be sent to VegBank. One could also create an XML document and load this without using VegBranch. This is for advanced users with much experience with our data model only. See the VegBranch topic in this FAQ for more information about VegBranch and loading plots.
VegBranch is an MS-Access (2000 or higher) database that allows users to import or enter data manually for import into the central VegBank database. It also allows users to add new plants and communities, enter new methods, projects, references, and parties. Furthermore, one can download plots from VegBank and read them into VegBranch. For more information on VegBranch, please see the overview of VegBranch.
There are several different ways that one can protect plot data in VegBank. The first option is to scramble the latitude and longitude so that the exact location of the plot is not known. This allows full access to the other data about the plot. This is generally sufficient for protecting endangered species. You can set the confidentiality status to a distance (i.e. 1km, 10km, 100km) in VegBranch for each plot, or in the Metadata form for all plots. The field in question is plot.confidentialityStatus (Plot Data Loading table, confidentialityStatus in VegBranch).
You can also specify confidentiality and allow no access to your plots until your embargo has expired. To do so, you should select a confidentiality status of "Full embargo." Eventually, we will support a middle level, where plots are embargoed, but users may request permission from the plot owner to view the plot. This is not yet implemented, however.
Note that if you make plots confidential, you must also provide a reason for the confidentiality in the plot.confidentialityReason field. This is not a publicly viewable field.
Yes, we do accept data from countries outside of North America, but consider VegBank's primary function to serve plots in North America. Eventually we hope to have several different VegBank systems which can be maintained and funded separately for different countries and regions. If you wish to submit plots from outside North America, there will be some challenges for you, especially in dealing with plant taxa, as we have only loaded plant concepts into VegBank that are found in North America.
Currently, we ask users to limit the number of plots that they provide to not more than 1000 plots without speaking to us directly about the plots. Some features of databases work well with a smaller amount of data and only very weakly with large amounts of data. We want to increase the size of VegBank somewhat gradually to help alleviate such technological issues.
If you have a plant taxon that isn't in the list of VegBank plants, you can add a new plant in VegBranch. The Species List loading table can be used to import data from a file that defines new plant concepts. Or, you can use a form for the Species List to fill in the different fields of this table. Please map your new concept onto the USDA list of plants if possible.
If you have a community that is not already in VegBank, you can add the community with VegBranch. VegBranch has a loading table called "Community Concept" that allows you to define a new community. It would be appreciated if you would correlate this community to any extant community concepts already in VegBank, preferable in the set of NatureServe communities so that other users might know how your new community maps onto the set of commonly accepted communities.
Advanced Questions
Our data model is a complex set of tables that comprise our relational database. More information about these can be seen with our data-dictionary and our ERD (Entity Relationship Diagram). The data dictionary provides information about each field and table in our database, such as data type, definition, if it is a required field, and what other field it may reference (foreign key). The ERD is a way of visualizing the tables and fields of our database. This information will only be useful to users who have some previous database experience.
Currently, there is only one VegBank. We have plans to allow other groups to use our software to create their own versions of VegBank, with the set of VegBank databases and website communicating to each other. This way, you could query for plots with a particular species in it and get results from plots in different databases. This will allow different organizations to maintain and fund their own plot archives, while still keeping the ability to share and compile plot datasets for users.
This space is intentionally left blank so that bookmarks on this page will take you to the correct part of the FAQ.